在Kubernetes安装
在现有Kubernetes集群上部署TensorFusion
前提条件
- 创建包含NVIDIA GPU节点的Kubernetes集群
- 安装Container Toolkit,一般云厂商的Kubernetes发行版可能已经内置
- 如果您不希望使用TensorFusion的控制台功能,可以参考纯本地化部署
指南中的安装过程大约需要2-4分钟完成
步骤一:安装TensorFusion
注册账号后访问TensorFusion控制台
复制一键接入命令,在Kubernetes集群中运行,如果需要定制Helm Chart的变量,参考此文档:Helm Chart Reference:
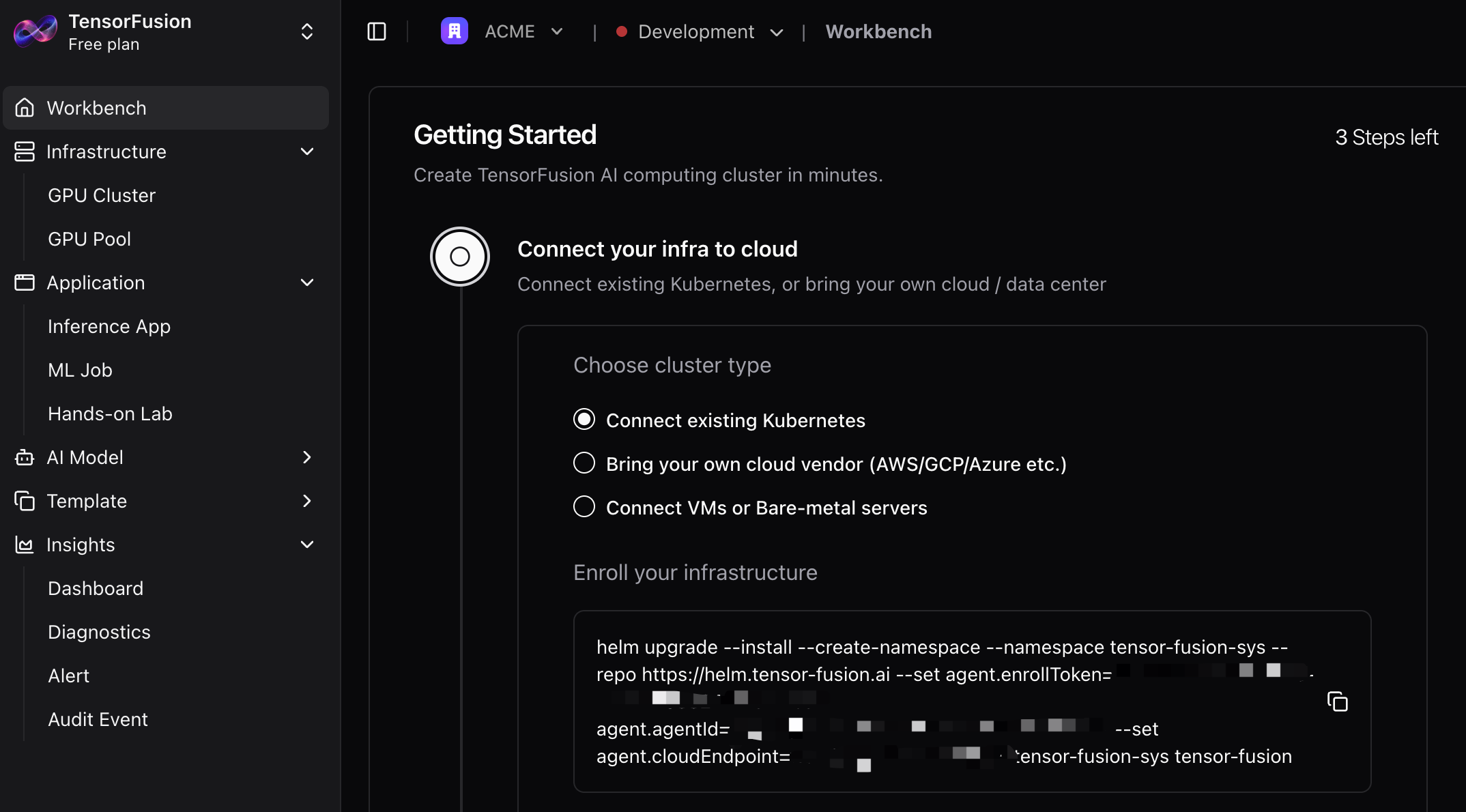
步骤二:应用定制资源
当agent就绪后,在控制台点击"预览"并"部署"按钮,一键应用云端的资源配置清单:
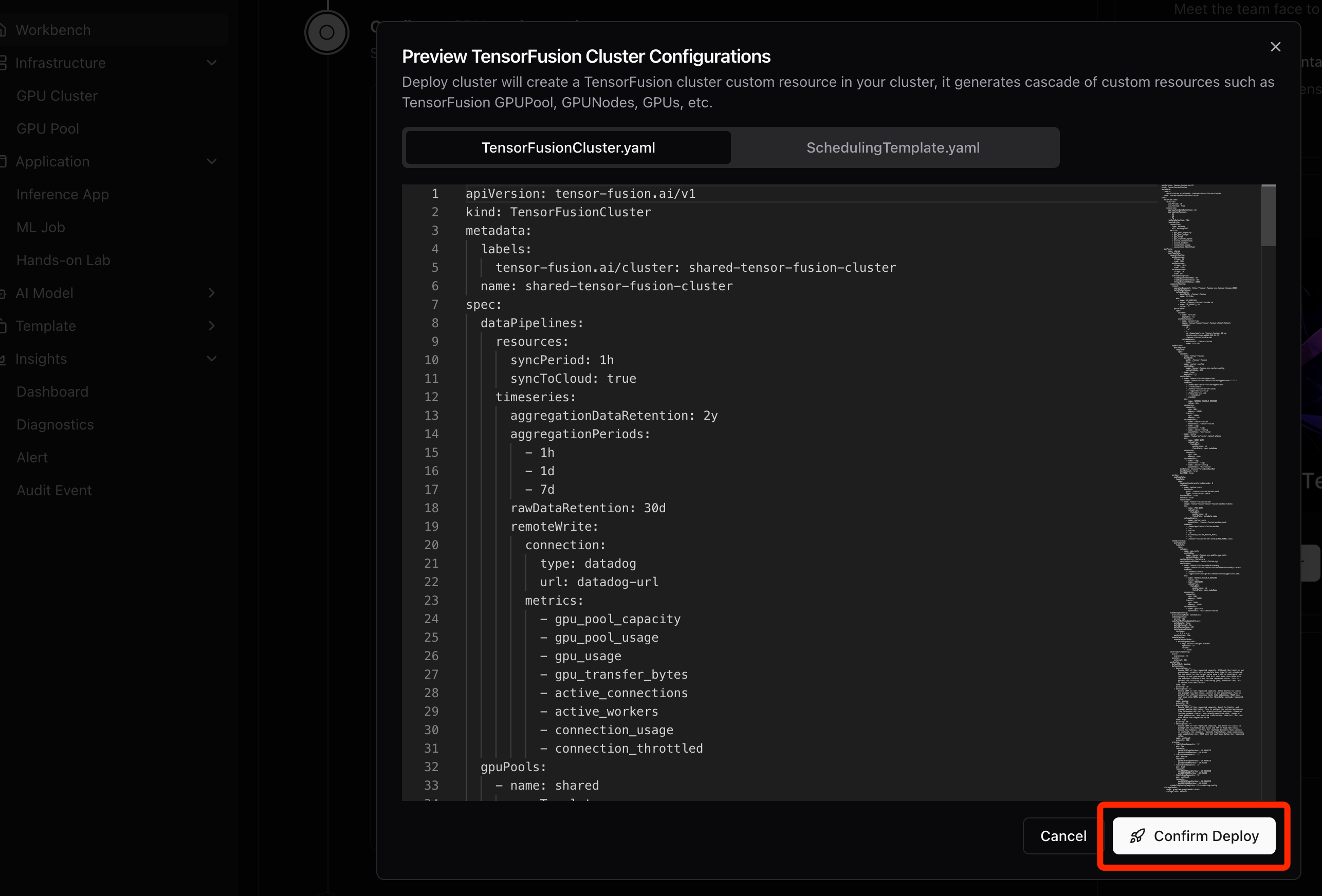
步骤三:部署验证
当状态显示就绪时,点击"Deploy Inference App"启动PyTorch容器进行验证:
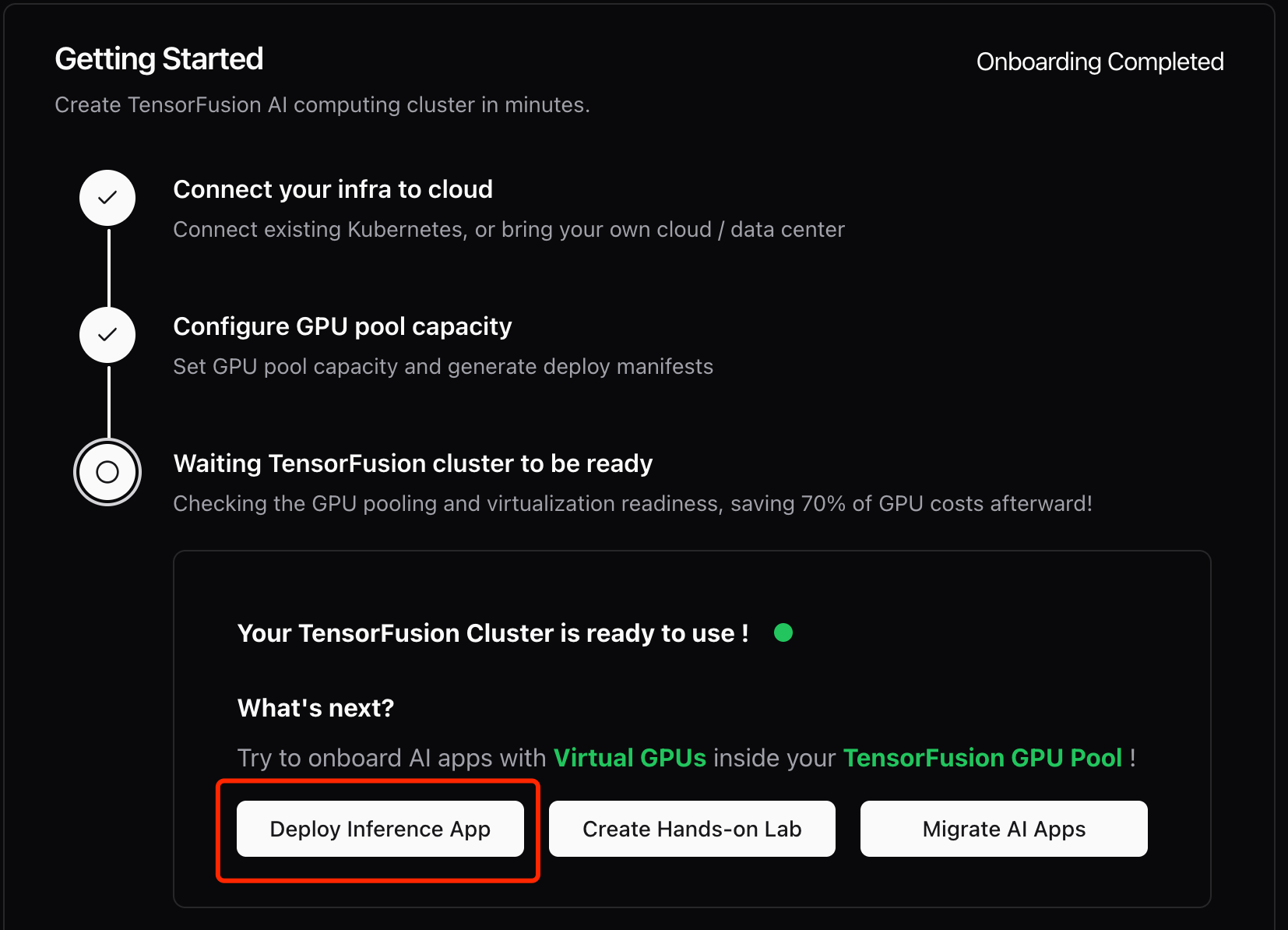
示例部署清单(已启用TensorFusion vGPU资源配置):
# simple-pytorch.yaml
# kubectl apply -f simple-pytorch.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pytorch-example
namespace: default
labels:
app: pytorch-example
tensor-fusion.ai/enabled: 'true'
spec:
replicas: 1
selector:
matchLabels:
app: pytorch-example
template:
metadata:
labels:
app: pytorch-example
tensor-fusion.ai/enabled: 'true'
annotations:
tensor-fusion.ai/inject-container: python
tensor-fusion.ai/tflops-limit: '10'
tensor-fusion.ai/tflops-request: '20'
tensor-fusion.ai/vram-limit: 4Gi
tensor-fusion.ai/vram-request: 4Gi
spec:
containers:
- name: python
image: pytorch/pytorch:2.6.0-cuda12.4-cudnn9-runtime
command:
- sh
- '-c'
- sleep 1d
restartPolicy: Always
terminationGracePeriodSeconds: 0
dnsPolicy: ClusterFirst执行以下命令验证GPU资源分配:
nvidia-smi
# 预期显存为4Gi,而不是显卡的总显存数量执行以下脚本,可在虚拟GPU中运行Qwen3 0.6B,验证TensorFusion
pip config set global.index-url https://pypi.mirrors.ustc.edu.cn/simple
pip install modelscope packaging transformers accelerate
cat << EOF >> test-qwen.py
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="cuda:0"
)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
EOF
python3 test-qwen.py方案二:纯本地化部署
如需完全本地化部署(不使用高级功能),可参考纯本地部署方案,但此模式无法使用TensorFusion控制台的管控台功能。
卸载TensorFusion
运行如下命令一键卸载所有组件
# 可指定 KUBECONFIG 环境变量
curl -sfL https://download.tensor-fusion.ai/uninstall.sh | sh -